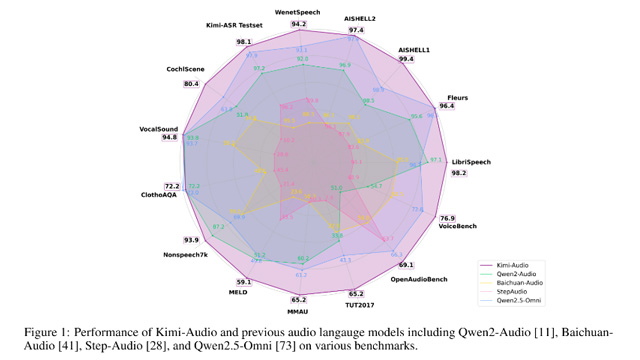
Moonshot AIは、新たな汎用音声基盤モデル「Kimi-Audio」をオープンソースで発表した。Kimi-Audioは音声認識、音声理解、音声対話、音声からテキストへの変換など、幅広い音声タスクに対応できる設計となっている。公開された結果では、10以上の音声ベンチマークにおいて総合性能で首位を獲得し、従来モデルを大きく上回る実力を示した。
Kimi-Audioは、音声トークン変換器(Audio Tokenizer)、音声大規模モデル(Audio LLM)、音声トークン復元器(Audio Detokenizer)という3つの主要コンポーネントで構成される。音声入力を離散的なセマンティックトークンと連続音響ベクトルに変換し、豊かな意味表現と音響情報を同時に保持。これにより、単一のモデルフレームワークで多様な音声言語タスクに柔軟に対応できる。
データ構築においては、約1300万時間に及ぶ多言語・音楽・環境音を含む音声データを用いた事前学習を実施。さらに音声理解、対話、音声テキスト変換タスクに対応した30万時間超のデータで監督微調整(SFT)を行った。音声・テキスト交錯訓練などの工夫により、マルチモーダル能力も高められている。
GitHub上では、Kimi-Audioの推論コード、モデルチェックポイント、ならびに標準化された評価ツールキットも無償公開されている。ユーザーは、事前学習済みモデルを用いた推論や、各種ベンチマークでの独自評価を容易に行うことができる構成となっている。
性能評価では、LibriSpeech ASRベンチマークで1.28%の低WER(語彙誤り率)を達成。MMAU、VocalSound、VoiceBenchといった複数の音声理解や対話基準テストでも最高水準のスコアを記録した。音声からテキストへの指令遂行や推論タスクでも高い成績を収め、さらに音声対話能力においてもGPT-4oに迫る水準の総合スコアをマークした。
Kimi-Audioはオープンソース公開によって、音声AI技術の普及と発展に大きく寄与する存在となることが期待されている。