Infinigence AI(無問芯穹)は、行列演算と通信操作の並列実行による性能最適化を目的とした新手法「FlashOverlap」を発表した。従来の張力分割型や演算融合型アプローチとは異なり、CUDA計算カーネル内部に信号フラグを埋め込むことで、計算の途中段階で通信処理を非同期に起動できる構造となっている。
通信操作にはNCCLを活用し、AllReduce、ReduceScatter、All2Allなど主要な集合通信方式と連携。計算と通信を別のStreamに配置し、信号フラグをトリガーに通信を開始する非侵入型の設計を採用している。
GPUのWave単位スケジューリングを活用することで、同一Wave内のTile群を一括で通信対象とし、通信効率と並列性を両立。Tileの再配置と復元にはMap Tableを導入し、Element-wise演算内で補正処理を実行することで性能を損なわずに整合性を維持する。
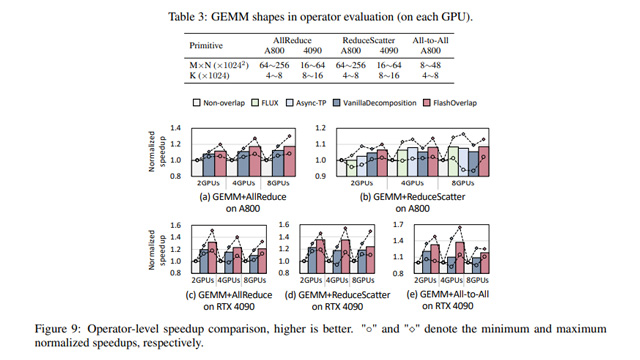
4090およびA800を用いたベンチマークにおいて、従来のSOTA手法と比較して1.07〜1.65倍の性能向上を達成。特に通信ボトルネックが深刻な推論や分散学習環境で効果を発揮する。
本技術はGitHub上でオープンソースとして公開されており、詳細な理論や実験はarXivの技術報告および知乎の公式解説記事にて確認可能。また、同社の製品群や研究成果は公式サイトからも閲覧できる。