ファーウェイのPanGu(盤古)チームは、中国国産のAscend NPUを6000枚以上使用した大規模クラスタ上で、7180億パラメータのMoE(Mixture of Experts)モデル「PanGu Ultra MoE」の安定訓練に成功した。これは従来、NVIDIA製GPUに依存してきた大規模モデル訓練において、完全な自立を象徴するブレークスルーとなる。
この成果は、大規模モデル訓練に伴う「四大課題」──アーキテクチャ最適化、動的負荷分散、通信効率、ハードウェア適合──を、ファーウェイ独自のシステム最適化技術で解決した結果だ。PanGuチームは、MoE構造の選定から始まり、細粒度専門家と共有専門家を組み合わせたアーキテクチャを設計。並列処理では、TP(テンソル並列)×EP(エキスパート並列)×DP(データ並列)に加え、VPP(仮想パイプライン並列)を組み合わせた48路構成を採用した。
また、分散通信の効率化では、Hierarchical EP Communication(階層的エキスパート通信)と前後計算を相互に重ね合わせるAdaptive Pipe Overlap Mechanismを導入。従来、通信時間の多くが露出していたEP通信において、前向き・後向き計算と組み合わせることで、通信の待機時間を大幅に削減した。
メモリ使用の最適化には、不要な再計算を避けるモジュール単位の再構成とTensor Swappingを活用し、必要なデータだけをNPUから一時的にCPUに移して効率化。さらに、動的な負荷分散機構により、Transformer層ごとの専門家パラメータと状態をクラスタ内で再配置し、演算効率(MFU)を10%向上させた。
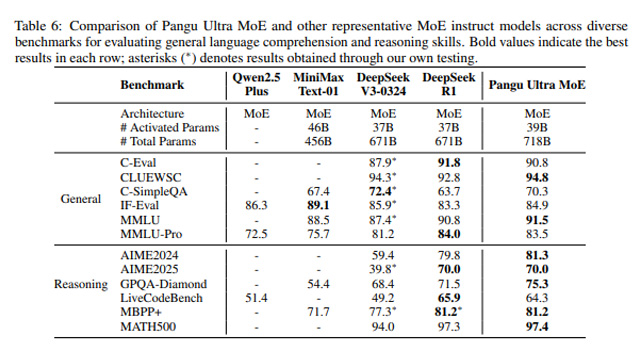
ベンチマークでは、CLUEWSC(94.8)、MMLU(91.5)などの言語理解タスク、AIME2024(81.3)、MBPP+(81.2)といった数学・コード生成タスクで高水準の成績を記録。通用的な対話性能に加え、計算力や論理思考を要する分野でも実用的な性能を示した。
加えて、PanGu Ultra MoEは各タスクに応じて異なる専門家モジュールを動的に活性化させることができる。ネットワーク層ごとの専門家割り当てには明確な違いがあり、これはモデルの専門性の高さと冗長性の低さを示す。さらに、共有専門家とルーティング専門家が均衡に出力へ貢献している点も、モデルの安定性と表現力の鍵となっている。
これらの成果は、ファーウェイのAscend NPUとその周辺エコシステムが、大規模AI訓練において世界水準に達したことを示すものであり、今後の中国AI産業の自律的発展に向けた重要な一歩となる。PanGu Ultra MoEは、産業界全体の高度なAI化に貢献し、グローバルな技術競争においても中国の競争力を象徴する存在となりつつある。