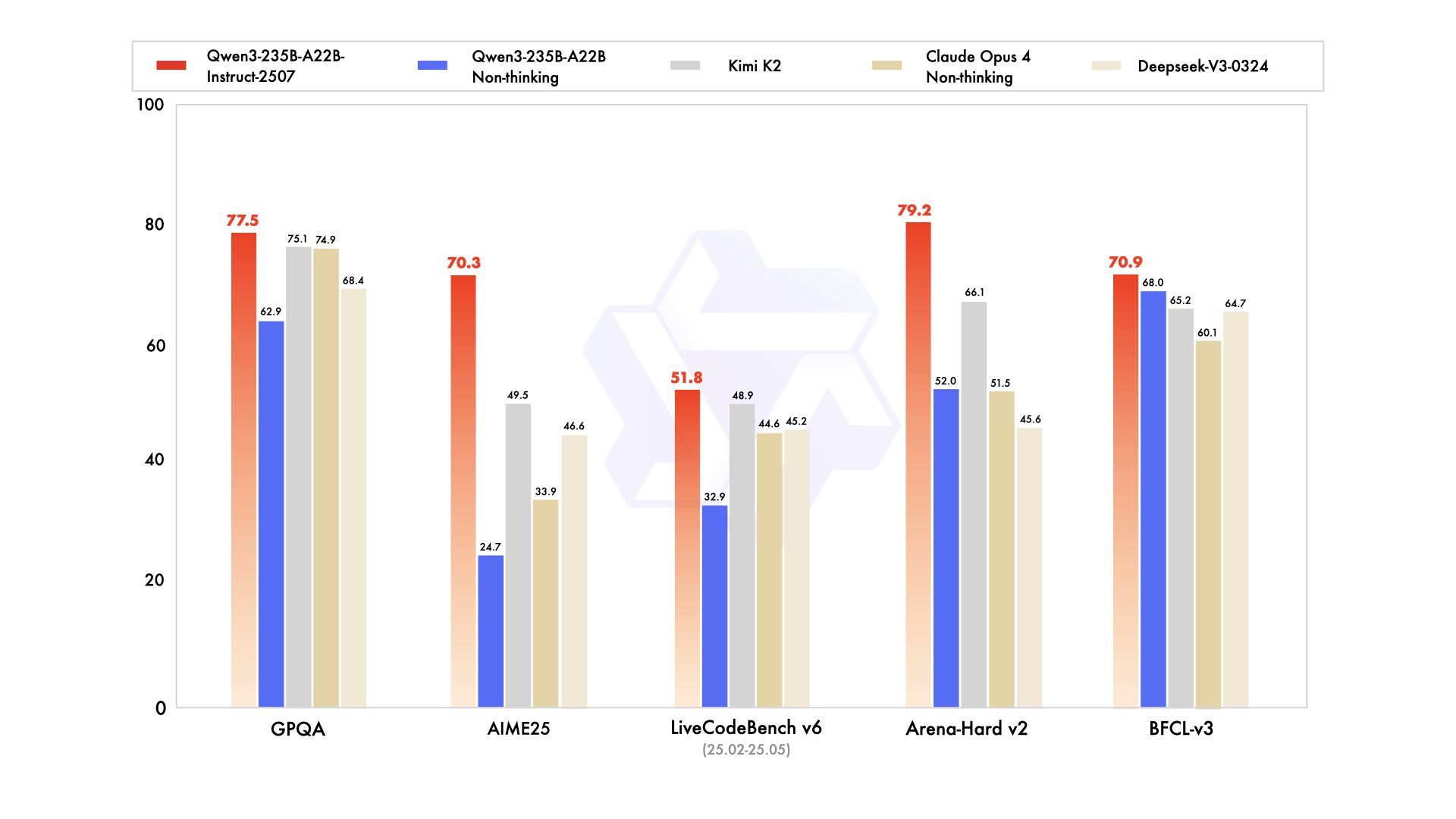
アリババのAI研究機関であるTongyi Labは、旗艦LLM「Qwen3」シリーズの最新版として「Qwen3‑235B‑A22B‑Instruct‑2507」を公開した。非思考モードに特化したこのモデルは、命令理解、論理推論、数学、プログラミング、多言語知識処理の能力が大幅に向上しており、事前の非思考版や他社の最先端モデルを大きく凌駕する。
たとえばGPQA(知識)で77.5、AIME25(数学)で70.3、LiveCodeBench(コーディング)で51.8を記録し、Claude Opus 4やDeepSeek‑V3を上回った。MMLU系や多言語ベンチマークでも高得点を維持し、特にユーザー志向性が求められる主観タスクや生成タスクでの整合性が向上している。
モデル構造は2350億パラメータのうち、推論時にはMoE形式で22億(8エキスパート)を活性化する設計。コンテキスト長は262,144トークン(約256K)に対応し、長文の文脈保持力にも優れる。従来必要だった `enable_thinking=False` の指定は不要となり、明示的な切替なしで非思考モードが発動する。
Hugging FaceではFP16形式の`safetensors`分割ファイルに加え、推論負荷を軽減したFP8版、`vLLM`や`llama.cpp`などに対応した形式も配布されている。API経由での利用や、Qwen-Agentによるツール呼び出しとの統合も可能で、エージェント用途への応用も視野に入る。
推奨設定では、Temperature=0.7、TopP=0.8、TopK=20といったサンプリング条件が紹介されており、16,384トークンまでの生成を想定した使い方が推奨されている。