アリババの研究機関であるTongyi Labは、コード生成に特化したエージェント型大規模言語モデル「Qwen3-Coder」を正式発表した。代表モデル「Qwen3-Coder-480B-A35B-Instruct」は、4800億パラメータのMoE(Mixture of Experts)構造を採用し、そのうち350億パラメータがアクティブに動作する。文脈長は標準で256Kトークンに対応し、YaRNを用いることで最大1Mトークンまで拡張可能とされ、巨大なリポジトリや動的データの処理にも対応する。
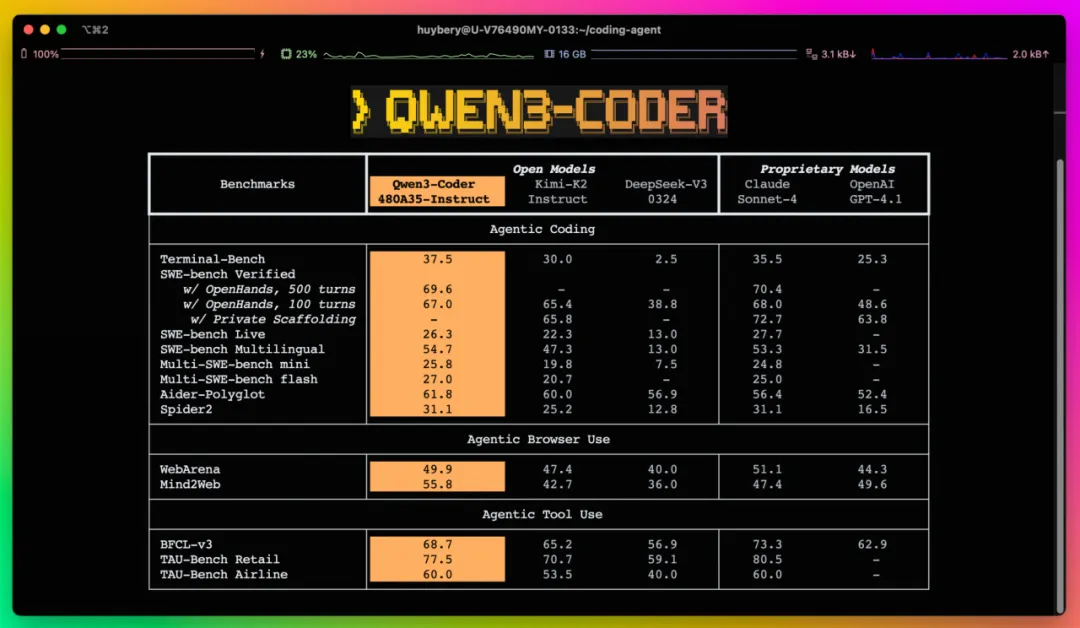
Agentic Coding、ツール操作、ブラウザ操作といったエージェント型タスクにおいて、Qwen3-CoderはオープンソースモデルとしてSOTA(最先端)の性能を記録し、Claude Sonnet4と並ぶ水準を実現。これに伴い、同モデル専用のCLIツール「Qwen Code」も公開された。Gemini CLIをベースに構築され、プロンプト適応やAPI接続が最適化されており、OpenAI互換のSDKやClaude Code、Clineなどの他ツールとの統合も想定されている。
学習には、コード比率70%を占める7.5TBの高品質データを使用し、既存のQwen2.5-Coderによるデータ再生成・最適化を通じて全体の品質を向上。後訓練フェーズでは、解くのは難しいが検証が容易な実行駆動型タスク(Hard to Solve, Easy to Verify)に特化したCode RL(強化学習)を実施。さらに、SWE-Benchのような長期的な意思決定を要する課題にも適応すべく、最大2万環境を同時実行可能な阿里雲の基盤を用いたAgent RLも実装された。これにより、SWE-Bench VerifiedでもSOTA性能を記録している。
今後、Qwen3-Coderはさらなるモデルサイズの展開や、デプロイ効率の改善、自律的な性能向上(Self-Improving)に向けた研究を進めるとされており、AIによるソフトウェア開発の革新が加速していく見通しだ。